Data-Driven Strategies for Proactive Application Monitoring

In today’s digital-first world, businesses must prioritize application health to ensure seamless user experiences and maintain reputation. Data-driven application performance monitoring solutions are essential for continuous optimization and preventing potential problems before they disrupt critical services. This shift safeguards user experience, brand reputation, and business continuity, driving lasting value beyond IT.
Advanced analytics and real-time data collection provide actionable insights at every stage of the software lifecycle. Organizations can anticipate system vulnerabilities, fine-tune resource utilization, and systematically drive continuous process improvement by embracing solutions like https://www.eginnovations.com/product/application-performance-monitoring that harness external expertise and field-tested toolsets. This level of insight is critical for maintaining current service levels and supporting growth and scalability in increasingly hybrid IT environments.
The result is a culture of operational resilience, where teams fix problems quickly and actively work to avoid them altogether, boosting efficiency and customer satisfaction over time. Ultimately, businesses that invest in robust application performance monitoring position themselves to outpace competitors, respond to market changes with agility, and deliver superior digital experiences across every user touchpoint.
Understanding Proactive Application Monitoring
Proactive Application Monitoring is an ongoing process of collecting, analyzing, and interpreting application performance data to head off issues before they reach end users. It is a significant departure from traditional reactive approaches. IT teams are often caught off guard, scrambling to resolve problems after they have already caused user disruption or business loss. Proactive strategies instead focus on the early identification of anomalous patterns, subtle performance degradations, resource shortages, or configuration drift—long before these warning signs spiral into service-impacting incidents. By leveraging these early indicators, organizations can take decisive action, maintaining the quality and integrity of the user experience.
The importance of proactive application monitoring is amplified in sectors where even small amounts of downtime or non-compliance with regulations can lead to major repercussions, whether financial, legal, or reputational. This monitoring approach provides IT leaders with the transparency and context needed to quickly pinpoint potential problems, prioritize responses, and decrease mean time to recovery (MTTR). The cumulative effect is not only a reduction in costly outages but also an enhancement of business growth and stakeholder confidence, as robust monitoring environments ultimately ensure that IT agility is closely aligned with evolving business demands.
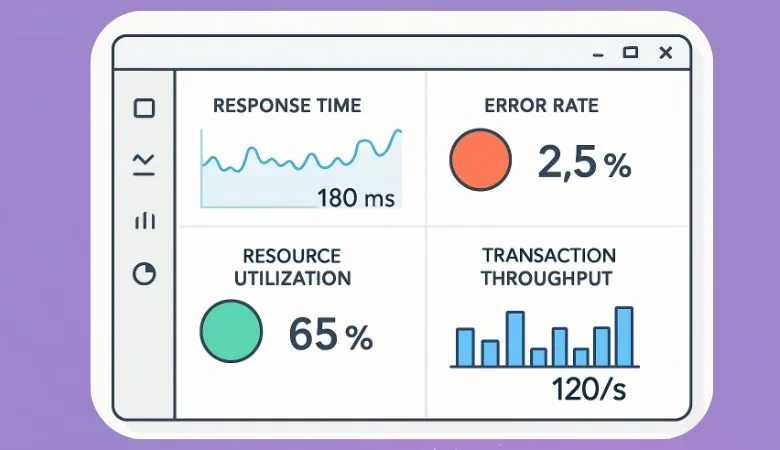
Key Metrics to Monitor
Successful proactive monitoring hinges on capturing, analyzing, and acting upon the right set of metrics—those vital signs that convey real-time application health and reliability. Precision and relevance are key: too few metrics can leave teams blind to critical risks, while too many lead to information overload and alert fatigue. The metrics most essential for insight-driven interventions typically include:
- Response Times: This measure measures how quickly applications answer user requests, signaling emerging slowdowns or performance regressions before they escalate into noticeable bottlenecks or user frustration.
- Error Rates: Tracks the frequency of errors, failed transactions, or software exceptions, helping IT identify points of failure or instability and prioritize areas for improvement or code refactoring.
- Resource Utilization: Provides granular visibility into CPU, memory, disk, and network usage, helping teams foresee and prevent capacity crunches that could lead to outages or degraded performance under load.
- Transaction Throughput: Assesses the number of operations, requests, or transactions handled within given intervals, offering insight into how well the system manages overall load and how it scales at peak demand.
Harnessing consolidated dashboards and automated alerting based on these critical metrics empowers IT teams to track historical trends, forecast future stress points, and swiftly respond to evolving conditions. In doing so, organizations can maintain service quality and continuously optimize application environments across a broad set of business scenarios.
Leveraging AI and Machine Learning
Artificial Intelligence (AI) and Machine Learning (ML) represent game-changing advancements for modern proactive monitoring strategies. Rather than relying solely on static, manually defined thresholds—which can miss nuanced or rapidly changing problems—AI and ML leverage vast datasets and learn from historical patterns, uncovering early indicators of trouble that would be imperceptible to human eyes or traditional tools. These algorithms continually refine their predictions by assimilating new data, identifying emerging trends, and distinguishing anomalies from benign spikes in application activity.
For organizations, this means AI/ML-empowered platforms can forecast hardware failures, predict unplanned workload surges due to marketing campaigns or seasonal spikes, and even trace the root causes of intermittent and hard-to-replicate issues. Automating these complex analyses reduces dependence on manual investigation, permitting quicker and more focused responses. Over time, these intelligent strategies drive IT operations toward a self-healing posture, where automatic remediation steps can be triggered before end users ever notice a problem.
Implementing Predictive Analytics
Predictive analytics marks the evolution from basic monitoring toward data-driven foresight and intelligent planning. By transforming historical monitoring data into actionable intelligence, organizations can leverage statistical models and machine learning tools to estimate when and where system failures or slowdowns are most likely to occur. This empowers teams to proactively prioritize at-risk areas for mitigation, allocate resources more cost-effectively, and strategically plan bigger initiatives, such as system upgrades or migrations, to minimize impact.
Hosting predictive analytics within your monitoring stack also delivers an operational edge by significantly reducing firefighting and unplanned downtime. It enables leaders to see beyond day-to-day incidents, introducing more discipline to infrastructure planning, maintenance scheduling, and scaling decisions—all critical for ensuring uninterrupted business services. Companies that embrace predictive analytics not only support robust service levels and operational resiliency but also secure a lasting competitive advantage by turning potential risks into opportunities for improvement and innovation.
Best Practices for Effective Application Monitoring
The success of proactive monitoring relies on more than implementing state-of-the-art tools; it depends on coordinated operational discipline, collaborative culture, and continuous learning. The following best practices are fundamental to creating monitoring systems that not only prevent issues but elevate the entire IT and business ecosystem:

- Establish Clear Objectives: Base monitoring goals on quantifiable metrics tied to business-critical processes and key customer touchpoints, so efforts are aligned with outcomes that truly matter.
- Implement Real-Time Monitoring: Deploy technologies capable of delivering immediate, context-rich feedback, empowering teams to detect and address issues before they become significant problems.
- Automate Incident Response: Integrate orchestration tools and runbooks that enable instant, pre-scripted interventions when anomalies are detected, minimizing both time-to-resolution and human error.
- Regularly Review and Update Metrics: Commit to revisiting and evolving the set of monitored metrics as applications, business priorities, and customer expectations change, ensuring ongoing relevance and accuracy.
- Foster Cross-Departmental Collaboration: Break down silos between IT, DevOps, product, and business stakeholders for unified monitoring initiatives, aligning technical monitoring with overarching strategic goals.
Continuous training, upskilling, and knowledge-sharing across teams can add an additional layer of effectiveness, building organizational confidence and flexibility to address emerging technology or business challenges as a unified force.
Future Trends in Application Monitoring
The landscape of application monitoring is rapidly evolving, propelled by ongoing advances in automation, real-time analytics, and holistic observability. As businesses accelerate their digital transformation journeys, the following trends are expected to play a transformative role:
- Integration with Edge Computing: Distributed monitoring frameworks now extend to the edge, allowing unparalleled responsiveness and deep insights for Internet of Things (IoT) platforms and environments where ultra-low latency is vital for business operations or safety.
- Adoption of Observability Practices: The convergence of logs, metrics, and application traces delivers a unified, context-rich perspective of complex systems, making it easier to map dependencies, root causes, and end-to-end user journeys in multifaceted IT landscapes.
- Utilization of Digital Twins: Creating virtual replicas of production environments enables teams to model scenarios, stress test changes, and conduct rapid experimentation—all without endangering live systems or negatively impacting users.
Staying at the forefront of these developments enables organizations to continuously refine their application monitoring approaches and maintain the agility to respond to both emerging technological forces and business imperatives.
Adopting data-driven, proactive application monitoring is more than just a technology upgrade—it’s a forward-thinking investment in uptime, user experience, and long-term business success. By transforming insight into action, proactive strategies empower organizations to swiftly illuminate and mitigate the risks that might otherwise go unseen, making resilience and innovation ongoing hallmarks of their digital operations.